Baseline Policies
This document describes the baseline policies available in the Collective Crossing environment. These policies provide simple reference implementations for comparison with more sophisticated multi-agent reinforcement learning approaches.
Available Policies
Greedy Policy
The Greedy Policy (GreedyPolicy) implements a simple greedy approach where agents move directly toward their destinations without considering other agents:
- Boarding agents: Move directly toward the tram door, then to their destination
- Exiting agents: Move directly toward the tram door, then to their destination
- Behavior: Agents don't coordinate and move as directly as possible
- Randomness: Supports epsilon-greedy exploration with configurable randomness factor
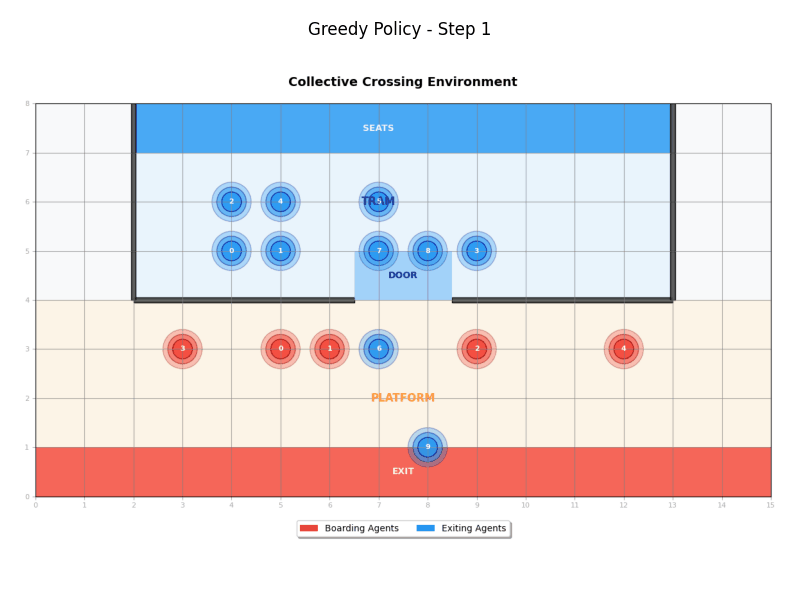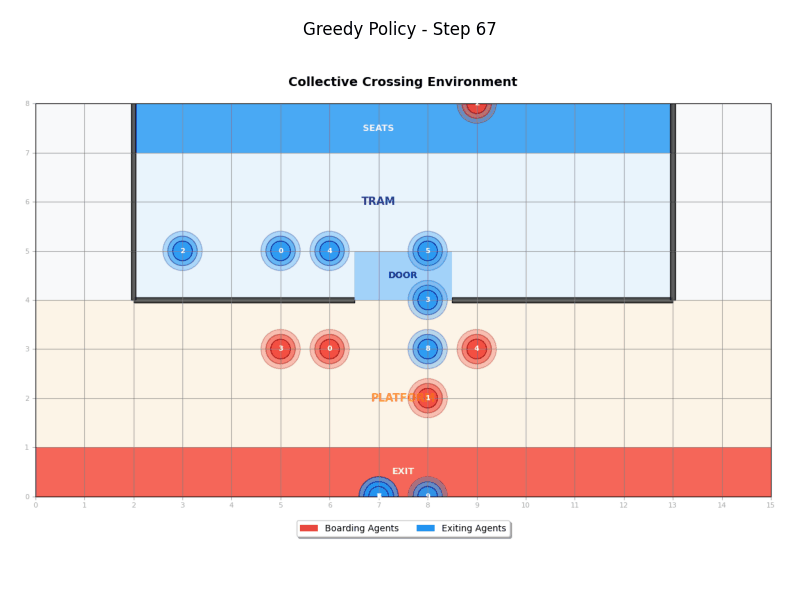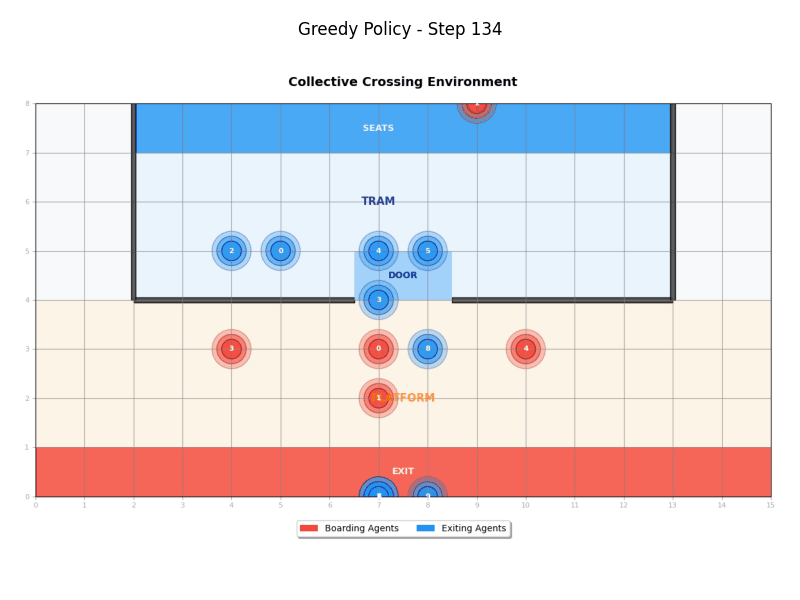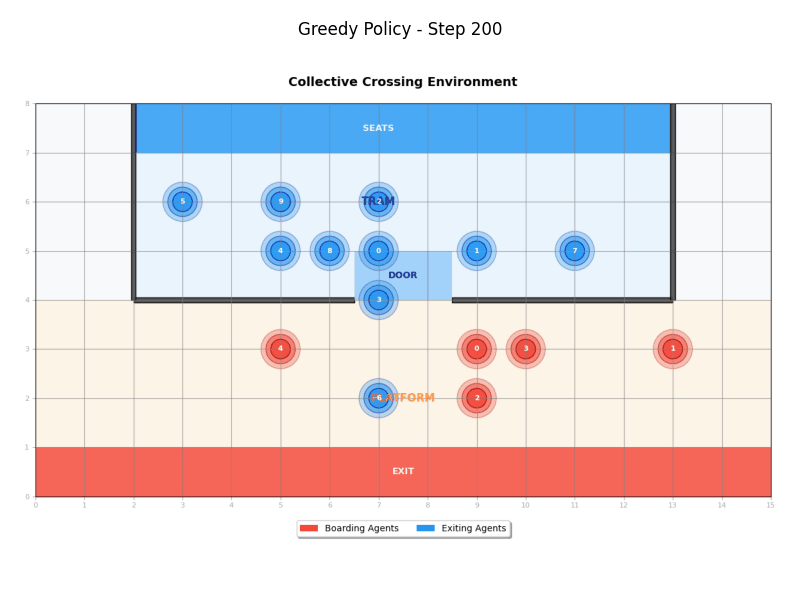
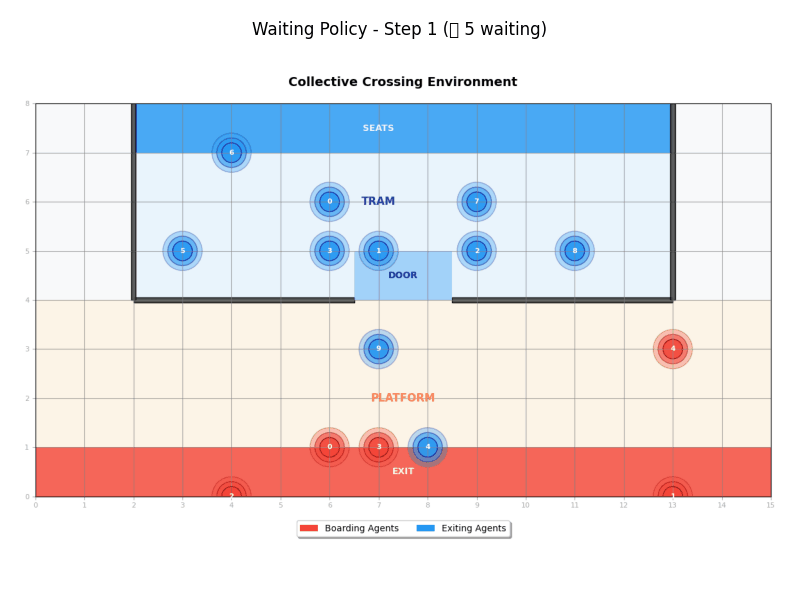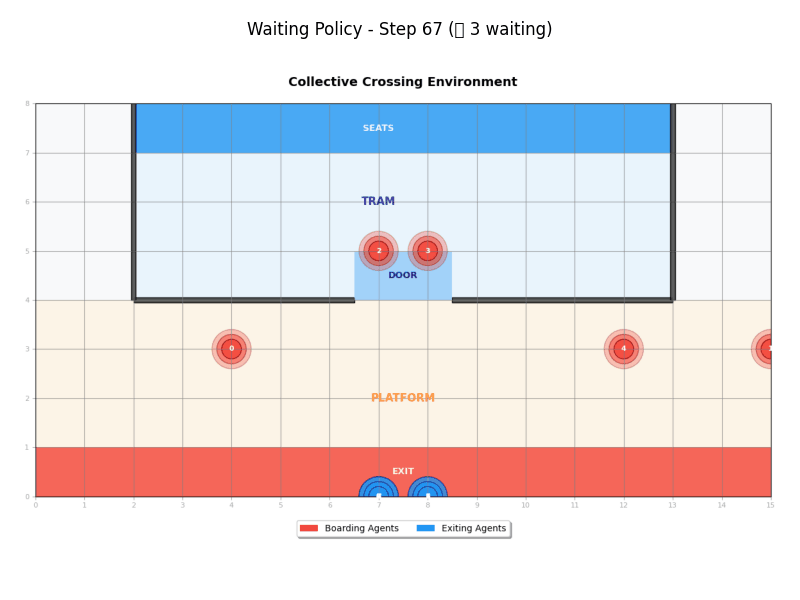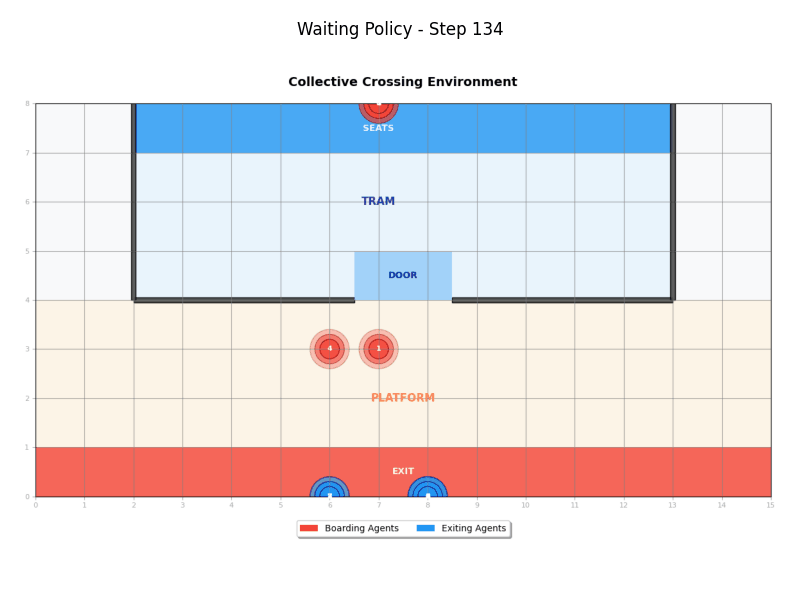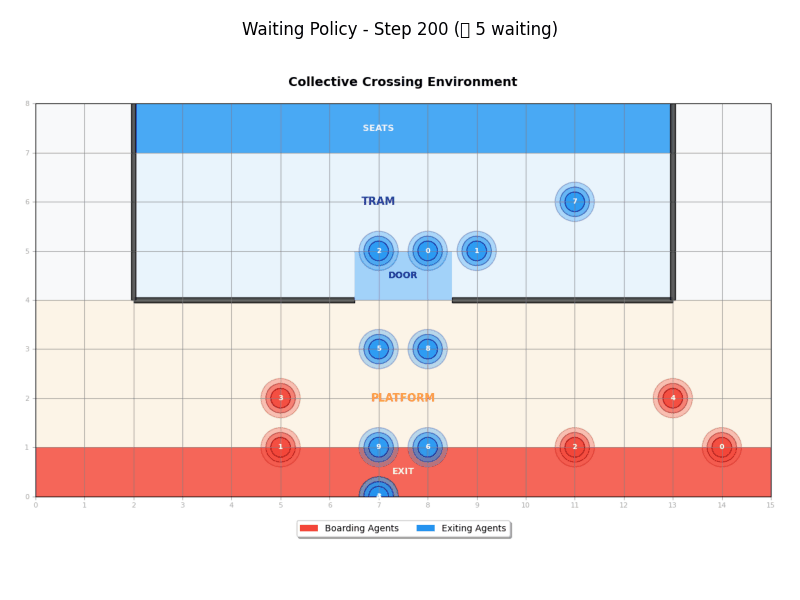
Waiting Policy
The Waiting Policy (WaitingPolicy) implements a coordinated approach that separates exit and entry phases:
- Phase 1: Boarding agents wait until all exiting agents have completed their journey
- Phase 2: Once waiting period ends, agents use greedy movement toward destinations
- Coordination: Creates clear separation between exit and entry phases
- Randomness: Supports epsilon-greedy exploration with configurable randomness factor
Running Baseline Policies
Demo Scripts
Two demo scripts are available to run and visualize the baseline policies:
Greedy Policy Demo
python scripts/run_greedy_policy_demo.py
Features: - Runs greedy policy with configurable epsilon (randomness factor) - Generates animated visualization showing agent movement - Collects and displays performance statistics - Saves animation as GIF file
Waiting Policy Demo
python scripts/run_waiting_policy_demo.py
Features:
- Runs waiting policy with configurable epsilon (randomness factor)
- Generates animated visualization showing coordinated movement
- Collects and displays performance statistics
- Saves animation as GIF file
Configuration
Both scripts use the same environment configuration: - Grid size: 15×8 with tram door at positions 4-7 - Agents: 5 boarding agents, 10 exiting agents - Termination: Individual destination-based termination - Truncation: Maximum 200 steps - Reward: Constant negative step penalty (-1.0)
Customization
You can modify the scripts to: - Adjust environment parameters (grid size, number of agents, etc.) - Change epsilon values for exploration - Modify reward configurations - Customize visualization settings
Usage in Code
from baseline_policies import create_greedy_policy, create_waiting_policy
# Create policies
greedy_policy = create_greedy_policy(epsilon=0.1)
waiting_policy = create_waiting_policy(epsilon=0.1)
# Use in environment loop
for agent_id, observation in observations.items():
action = policy.get_action(agent_id, observation, env)
# Apply action...
Performance Comparison
These baseline policies serve as reference points for evaluating more sophisticated approaches:
- Greedy Policy: Fast but may cause congestion at bottlenecks
- Waiting Policy: Slower but avoids conflicts through coordination
Use these baselines to establish performance benchmarks when developing and testing new multi-agent reinforcement learning algorithms.